Master Recon : Outils et Techniques pour la reconnaissance

As a newcomer to the cybersecurity industry, I'm on an exciting journey of continuous learning and exploration. Join me as I navigate, sharing insights and lessons learned along the way
Dans cet article, nous allons explorer divers outils qui permettent de collecter des informations sur des cibles spécifiques lors de la phase de reconnaissance. Nous commencerons par des outils de Linked Discovery, une méthode qui permet d’explorer et extraire des liens et des ressources d'un site web. Pour cela, nous décrirons des outils comme GoSpider, Hakrawler et Katana.
Ensuite, nous parlerons des outils de CloudRecon tels que ScoutSuite, Crt.sh, Host.io, IPRange et CSPrecon, qui aident à analyser les infrastructures cloud. Par la suite, nous aborderons divers outils de collecte d’informations comme KarmaV2, un outil OSINT, Crunchbase et OCCRP.org .
Enfin, nous examinerons les techniques de Reverse WHOIS avec Whoxy.com, DomainTools et Whois, ainsi que le Reverse DNS en utilisant nslookup, dig, HakreDNS et WhoisXML.
Cet article fait suite à un précédent que j'avais écrit sur la reconnaissance lors d'un pentest, en partageant des outils comme Check_mdi, DNSCHEKER, ASNmap et des outils de scan tels que Naabu et RustScan. Le lien est disponible ici.
Bonne lecture :)
Linked Discovery
Linked Discovery est un processus qui consiste à explorer et à extraire des liens et des ressources d’un site web pour obtenir des informations sur une cible. Il permet d’identifier la structure des pages et les relations entre elles pour mieux comprendre comment un site est construit. On peut aussi y ressortir les sous-domaines et d’autres ressources cachées ou moins visibles.
GoSpider
GoSpider est un outil de reconnaissance écrit en langage Go, pour crawler ou extraire des données d’un site Web. Un crawler ou robot d’exploration est un programme ou un script automatisé destiné à collecter des informations sur des sites internet. GoSpider peut être utilisé lors de la reconnaissance pour identifier des liens, des ressources, des fichiers en lien avec un site spécifique.
La documentation officielle se retrouve sur GitHub.
Pour installer GoSpider, utilisez la commande suivante:
go get -u github.com/jaeles-project/gospider
Options
gospider -h: l’option-hpermet de lister toutes les options de GoSpidergospider -s [site.com/URL] -o [resultat.txt/.json]l’option
-sspécifie l’URL ou le site à analyser;l’option
-oenregistre les résultats dans un fichier;
gospider -s [site.com/URL] -c [INT] -d [INT]l’option
-cdéfinit le nombre maximal de requêtes simultanées lors de l’exploration du site (par défaut, il est fixé à 5);l’option
-ddéfinit la profondeur de lien à explorer lors du crawl. Cela signique qu’il explore d’abord l’URL initiale, ensuite les liens trouvés sur cette page, et ensuite les liens sur ces pages, et ainsi de suite. Il est fixé à 1 par défaut.
gospider -S [sites] -q --blacklist [ ]l’option
-Sspécifie un fichier texte contenant les URLS de sites à analyser;l’option
-qrend l’analyse plus concise et désactive les logs détaillés;l’option
--blacklistpermet d’exclure (blacklister) soit des extensions, des types de fichiers lors de l’analyse.
En parcourant la liste des options, vous aurez accès aux différentes manières d’utiliser GoSpider.
Hakrawler
Hakrawler est aussi un outil de reconnaissance utilisé pour explorer des sites web et extraire des informations comme des liens, des formulaires et des emplacements de fichiers . Aussi écrit en langage Go, il est utilisé lors de la phase de reconnaissance lors des tests de sécurité.
La documentation officielle se retrouve sur GitHub.
Pour installer Hakrawler, utilisez la commande suivante:
go get -u github.com/hakluke/hakrawler
Options
hakrawler -h: cette option affiche toutes les options de hackrawlerecho [URL] | hakrawler -t [INT] -d [INT] -t [INT] | grep "STRING"la commande
echoenvoie l’URL en tant qu’entrée à Hakrawler via le pipe|l’option
-tpour threads, définit le nombre de requêtes simultanées pour accélerer l’exploration. Cela permet de crawler plusieurs pages à la foisl’option
-ddéfinit la profondeur du crawll’option
-tfixe le délai dattente pour chaque requête. Passé ce délai, la requête d’exploration est abandonnée si elle ne recoit aucune réponsel’option
grepfiltre les résultats du hakrawler selon le string défini
cat sites.txt | hakrawler -subs -jsonle contenu du fichier “sites.txt” est lu (une URL par ligne) et redirigé à Hakrawler via le symbole pipe
|l’option
-subsindique qu’il faut analyser aussi les sous-domaines liés à chaque url dans le fichierl’option
-jsonretourne les résultats en format JSON
Katana
Katana est un outil d’exploration de sites web, écrit en Go, dévéloppé par Project Discovery. Il permet aussi d’analyser des sites web, d’y extraire des ressources cachées et identifer des vulnérabilitées potentielles.
La documentation officielle se retrouve sur GitHub.
Pour installer Katana, utilisez la commande suivante:
go install github.com/projectdiscovery/katana/cmd/katana@latest
Options
katana -h: cette option liste toutes les options de katanakatana -u [site.com] -d [INT] -e "STRING" -rl [INT] -o [results.json]l’option
-udéfinit le site ou l’URL à analyserl’option
-ddéfinit la profondeur d’exploration à partir du lien spécifiél’option
-eexclut divers éléments correspondants à la chaîne de caractère spécifiée. Cela peut être des chemins, des adresses IP, des sous-domaines etc.l’option
-rlfixe un nombre maximal de requêtes par secondes (150 par défaut)
cat file.txt | katana -jc -noicatpermet de lire un fichier qui contient une liste d’URLs (une par ligne) à explorerl’option
-jcactive l’analyse des fichiers JavaScriptl’option
-noipour no incognito désactive le mode incognito, l’historique de navigation est donc enregIstré
Toute la documentation et les options sont disponibles sur Github.
Cloud Recon
Le Cloud Recon est une phase de la reconnaissance qui consiste à identifier et analyser les ressources disponibles sur les services cloud. Il est utilisé pour découvrir des services cloud publiques, des configurations de sécurité potentielles, les bases de données, des machines virtuelles et bien d’autres.
ScoutSuite
ScoutSuite est outil open-source d’audit de sécurité qui permet d’analyser les configurations de sécurité des environnements cloud. Il fontionne avec plusieurs fournisseurs de services cloud tels qu’AWS, Azure Microsoft et Google Cloud Plateform et d’autres.
ScoutSuite collecte des données sur les configurations et génère des rapports détaillés pour soit identifier des vulnérabilités potentielles ou améliorer la sécurité.
La documentation officielle se retrouve sur GitHub.
Bien que ScoutSuit soit un outil open-source gratuit, l’utilisation des services cloud peut engendrer des coûts en fonction des ressources que vous souhaitez analyser.
Crt.sh
Crt.sh est un outil en ligne qui permet de rechercher et de consulter des certificats SSL/TLS pour divers domaines. Il peut être donc utilisé pour identifer par exemple des sous-domaines et services cloud utilisés par une organisation. Il utilise les données des Transparency Logs pour fournir des informations sur les certificats, ce qui peut aider à détecter des certificats non autorisés, donc des problèmes de sécurité. Les Transparency Logs, ou journaux de transparence, sont des systèmes conçus pour consigner les informations relatives aux certificats émis par les autorités de certification (CA). Lorsqu'un certificat SSL/TLS est émis par une autorité de certification (CA), une entrée correspondante est ajoutée à un ou plusieurs journaux de transparence, permettant ainsi à toute personne de la consulter.
Crt.sh est accessible via leur site web.
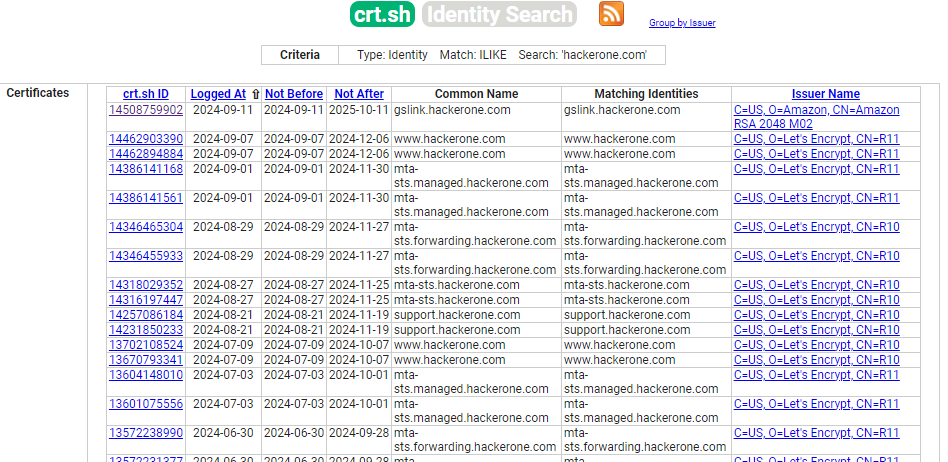
En effectuant une recherche sur le domaine “hackerone.com“, on voit donc une variété de sous-domaines associés, et la majorité des certifats émis par Let’s Encrypt.
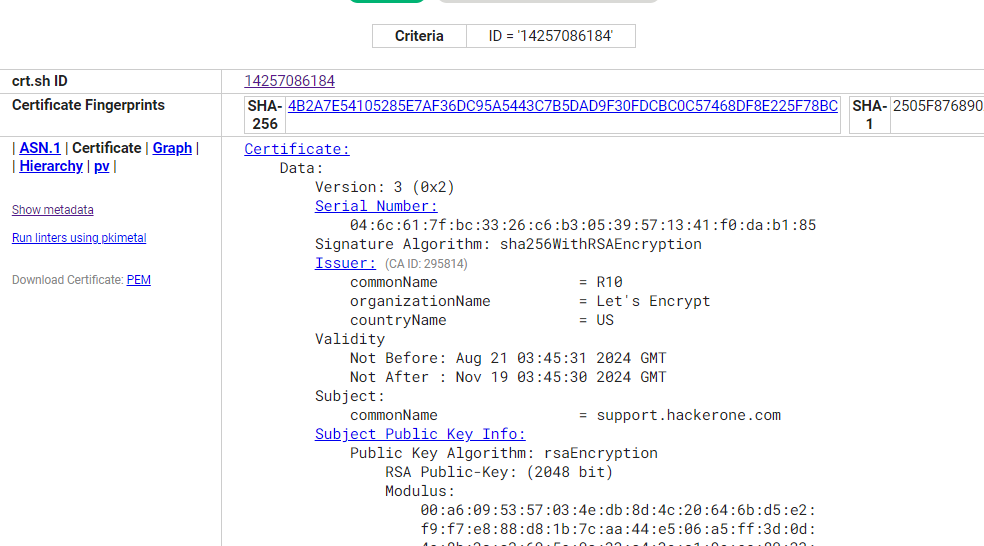
En cliquant sur un ID associé à un domaine, on obtient beaucoup plus de détails: l’émetteur du certificat, la validité, l’algorithme utitlisé pour le chiffrement (ici RSA avec une clé de 2048 bits), ainsi que les empreintes des certificats. La clé ici étant de 2048 bits est très sécurisée car suffisamemnt longue pour faire face aux tentatives de décryptage par force brute par exemple.
Host.io
Host.io est un service en ligne qui fournit des informations détaillées sur les domaines, les nouveaux domaines et les relations entre eux. Il permet de rechercher des données telles que les IP associées, les enregistrements DNS, des liens sortants, des backlinks et d’autres détails d’hébergement pour n’importe quel domaine et d'autres informations pertinentes. Host.io peut donc aider à comprendre l’infrastructure Cloud d’une organisation.
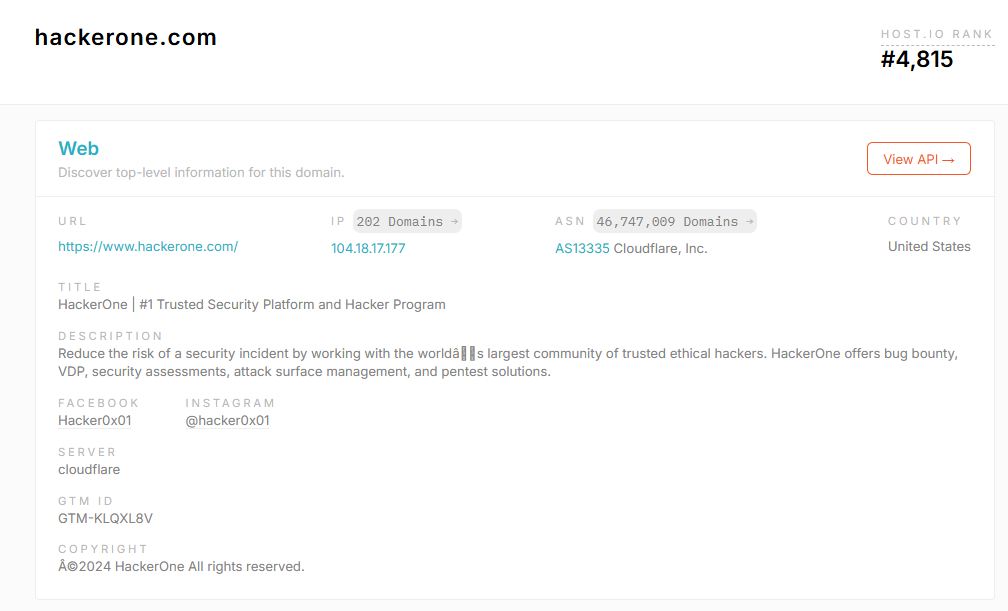
En recherchant le domaine “hackerone.com“, on a plusieurs informations:
l’adresse IP associée au domaine avec un lien vers d’autres domaines partageant la même IP
le numéro d’AS associé à Cloudflare, qui indique l’organisation qui gère le routage domaine
le serveur associé
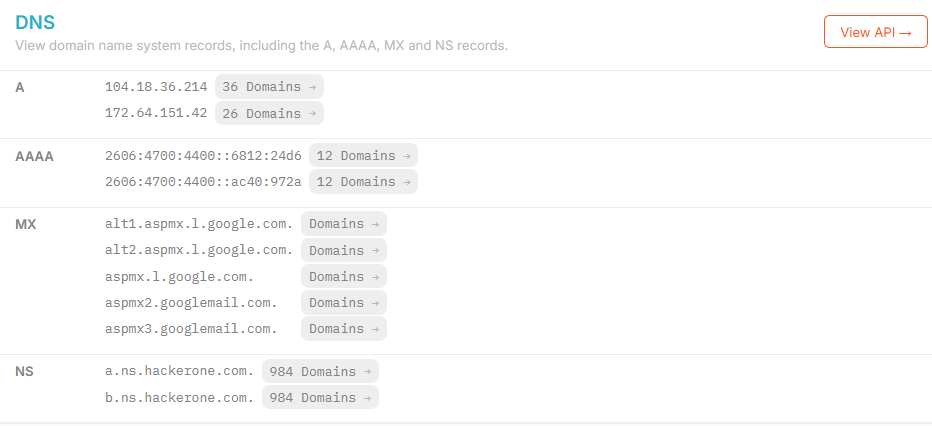
Une section montre aussi les enregistrements DNS, qui indiquent les adresses IPV4 (A Records), les adresses IPV6 (AAAA Records), les serveurs de messagerie (Mail Exchange).
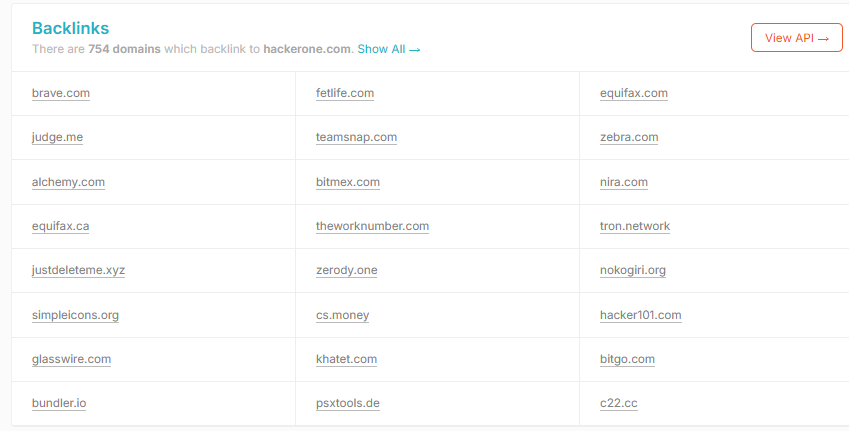
Les backlinks sont des liens entrants qui proviennent d’autres sites web, vers un domaine.
IP Range
IPRange est un outil qui permet d’énumérer toutes les plages d’adresses IP provenant de divers fournisseurs et services, tels que Google, Amazon, Microsoft, OracleTelegram, OpenAI, et bien d’autres avec des mises à jour quotidiennes. Il utilise des données et des listes provenant de sources publiques.
La documentation officielle se retrouve sur GitHub.
CSPRecon
CSPRecon est un outil qui permet d'identifier les ressources déployées dans des environnements cloud comme AWS, Azure, et Google Cloud, facilitant ainsi la reconnaissance des infrastructures. Il peut donc être utiliser dans la cadre du Cloud Recon pour analyser les configurations des ressources cloud et pour évaluer la sécurité.
Voici un lien vers un dépôt Github pour télécharger CSPRecon.
Exécutez la commande suivante pour télécharger CSPRecon:
go install github.com/edoardottt/csprecon/cmd/csprecon@latest
Vous devez avoir Go installé, sinon vous pouvez aussi l’installer avec Homebrew (MacOS) ou Snap(Linux).
Options
csprecon -h: cette option liste tout les options de CSPReconcsprecon -u [SITE] -d [DOMAIN]l’option
-upermet de spécifier un domainel’option
-dpermet de filtrer les résultats pour n'inclure que certains domaines (séparés par des virgules)
csprecon -l [liste] -v -jl’option
-lindique un fichier contenant une liste de domaines à analyserl’option
-vpermet d’afficher des informations détaillées lors de l’analysel’option
-jgénère une sortie au format JSON
Recherche d’informations
KarmaV2
KarmaV2 est un outil de reconnaissance OSINT qui permet de trouver des informations publiques et approfondies sur une cible. La documentation officielle se retrouve sur GitHub.
Vous pouvez installer KarmaV2 avec les commandes suivantes
Cloner le répertoire
git clone https://github.com/Dheerajmadhukar/karma_v2.gitInstaller shodan et le module python mmh3
python3 -m pip install shodan mmh3Installer le parser JSON JQ s’il n’est pas déjà installé
apt install jq -yInstaller httprobe
go install -v github.com/tomnomnom/httprobe@master cd httprobe go build main.go mv main httprobe sudo mv httprobe /bin/Installer Interface
git clone https://github.com/codingo/Interlace.git cd Interlace pip install -r requirements.txt sudo python3 setup.py installInstaller Nuclei
go install -v github.com/projectdiscovery/nuclei/v2/cmd/nuclei@latestInstaller Lolcat
apt install lolcat -yInstaller anew
git clone https://github.com/tomnomnom/anew.git cd anew go build main.go mv main anew sudo mv anew /bin/Créez un compte sur Shodan.io pour obtenir votre clé API Shodan
Insérez la clé dans le fichier
.tokendans le répertoire /karma_v2nano ./token SHODAN_API_KEY_FROM_SHODANLancer karma avec
bash karma_v2 -h
Dépendamment de votre système, il est possible de devoir exécuter karma_v2 dans un environnement virtuel.
Options
bash karma_v2 -h: pour voir la liste de toute les options de Karma_v2bash karma_v2 -d [DOMAIN] -l [INT] -ip -cvel’option
-dspécifie le domaine;l’option
-iprecherche des adresses IP associées à ce domaine;l’option
-lspécifie le nombre de résultats lors de la recherche. On peut spécifier -1 pour indiquer un nombre illimité de résultats.l’option
-cverecherche les vulnérabilités associées au domaine.
Les options
-d,-let les options pour le mode (-ipou-asnou-cveetc..) sont requises pour exécuter karma_v2L’option
-deepprend en charge toutes les options count, ip, asn, cve, favicon, leaks.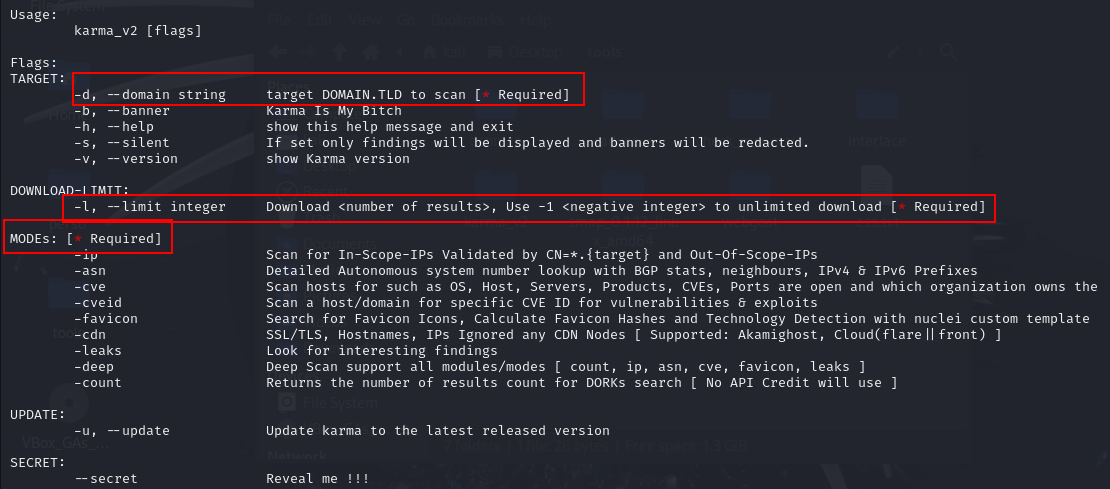
Crunchbase
Crunchbase est une plateforme payante qui donne des informations sur les entreprises et les investisseurs. Elle fournit des données permettant d’analyser les acquisitions des entreprises sur le marché comme les startups, et aussi les membres de l’entreprise.
OCCRP
L’OCCRP (Organized Crime and Corruption Reporting Project) est une organisation de journalisme d’investigation sur les sujets commes la corruption ou la criminalité. Elle reporte des informations sur des personnalités ou des entreprises impliquées dans des activités de corruption.
Il peut être très utile dans la phase de reconnaissance, pour la collecte d’informations, car il fournit des données détaillées, des rapports sur des entreprises ou individus impliqués.
ReverseWhois
ReverseWhois est une méthode qui permet d’identifer des noms de domaines en fonction des informations comme des noms, des adresses courriels etc. Autrement dit, plutôt que de chercher un domaine spécifique, on entre des informations sur une personne ou une organisation pour voir tous les domaines qu'ils possèdent.
Il existe plusieurs outils pour effectuer des recherches de Reverse Whois:
Whoxy
Whoxy.com est un service en ligne qui permet d'effectuer des recherches de Reverse Whois. Il permet de vérifier les domaines possédés ou contenant la recherche dans les enregistrements WHOIS. Cela peut inclure des recherches basées sur des noms, des adresses courriel, ou d'autres détails.

DomainTools
DomainTools est une entité qui fournit des services et des outils pour la recherche et l'analyse de noms de domaine. Elle offre des fonctionnalités de Reverse WHOIS avec son outil Whois Lookup.
REVDNS
Le Reverse DNS (REVDNS) est une méthode qui consiste à déterminer le nom de domaine associé à une adresse IP. Contrairement à une recherche DNS standard, qui consiste à convertir un nom de domaine en adresse IP, le Reverse DNS, fait la recherche inverse. Elle peut être donc très utile soit dans le cadre de la reconnaissance ou dans un BugBounty car en trouvant les domaines associés à une adresse IP, il serait possible d’identifier de potentiels services vulnérables ou encore des sous-domaines.
Il existe plusieurs outils pour effectuer des recherches de Reverse DNS:
Nslookup
C’est un outil en ligne de commande qui permet d’effectuer des requêtes DNS et aussi des recherches de ReverseDns. Il s’utilise avec la commande suivante pour le RevDNS:
nslookup IP_ADRESS
Dig
Dig est un outil en ligne de commande utilisé pour interroger les serveurs DNS et effectuer aussi des reverseDNS. Pour une recherche inverse, utilisez la commande:
dig IP_ADRESS
HakrevDns
HakrevDns est aussi un outil utilisé pour effectuer des recherches DNS inversées.
Le dépôt Github pour HakrevDns est disponible ici. Vous pouvez l’installer avec la commande suivante:
go install github.com/hakluke/hakrevdns@latest
Utilisez la commande hakrevdns -h pour afficher les paramètres de Hakrevdns.
WhoisXML
WhoisXML est un service qui propose des outils pour effectuer des recherches liées aux domaines, et aussi des recherches inversées DNS (REVDNS). WhoisXML fournit beaucoup plus d’informations sur les domaines, telles que les enregistrements DNS et l'historique des enregistrements. Il est aussi possible d’utiliser leur API pour intégrer ces fonctionnalités dans d’autres applications et outils.
Pour utiliser WhoisXML, il faut d’abord vous inscrire et obtenir une clé API. Ce service dispose d’un plan gratuit pour 500 requêtes. Si vous souhaitez un usage plus intensif, vous pouvez envisager un des abonnements.
NXDOMAIN (Non-Existent Domain)
Pour qu’une recherche inverse DNS fonctionne, il faut qu’un enregistrement PTR (Pointer Record) ait été défini pour cette adresse IP. Un enregistrement de type A associe un nom de domaine à une adresse IPV4 et un enregistrement de type PTR, lui associe une adresse IPV4 à un nom de domaine. Si l’enregistrement PTR n’a donc pas été défini par l’organisation, une tentative de reverse DNS ne renverra aucun résultat avec un statut NXDOMAIN (Non-Existent Domain).
Conclusion
La reconnaissance est une étape clé dans le processus de test d’intrusion ou de bug bounty. Il est donc important de recueillir le maximum d’informations qui vont être utiles lors de la phase suivante. En utilisant les outils et techniques présentés dans cet article, et bien d’autres, vous pourrez perfectionner votre méthode de reconnaissance. N'hésitez pas à expérimenter ces outils et à donner vos commentaires :)